DS1 Physics Informed Neural Networks
Bhavesh Shrimani (bshrima2@illinois.edu) https://bhaveshshrimali.github.io/
Introduction
This blog covers Physics Informed Neural Networks, which are basically neural networks that are constrained to obey physical constraints. The blog broadly discusses two directions:
In particular, it deals with two distinct types of algorithms, namely
- A new family of data-efficient spatio-temporal function approximators
- Arbitrary accurate RK time steppers with potentially unlimited number of stages
We know that deep neural networks are powerful function approximators. They can approximate a nonlinear map from a few – potentially very high dimensional – input and output pairs of data. However, the approximation does not take into account any underlying physical constraints imposed by fundamental principles (such as conservation laws) which are
often given in terms of PDEs. PINNs precisely solve this problem by regularizing the loss functions with these constraints. The resulting approximation enjoys both the power of deep neural nets as function approximators and obeying the underlying physical conservation laws.
PDEs
Let us consider a parametric nonlinear PDE
where denotes the latent (hidden) solution and is a nonlinear operator parametrized by . This encapsulation covers a wide range of PDEs in math, physics, atmospheric sciences, biology, finance, including conservation laws, diffusion, reac-diff-advec. PDEs, kinetics etc. The burger’s equation in d is an apt starting step to investigate if indeed PINNs can efficiently solve PDEs, and therefore the authors begin by applying PINNs to it.
The two directions highlighted above can now be restated in context of Burger’s equation as follows:
- Given what is (data-driven solutions of PDEs)
- Find that best describes observations (data-driven discovery of PDEs)
PDEs + PINNs
First, let us rewrite the PDE as
The next step consists of appending the loss function used for the training process (finding the parameters ) as follows:
where
Here consists of the approximation error at the boundary of the domain (initial and boundary conditions), and denotes the error incurred inside the domain. Also, specify the collocation points — the discrete points at which the physical constraints are imposed through a regularized (penalty) formulation. Another way to look at this is that helps to enforce initial and boundary data accurately, while imposes the structure of the PDE into the training process. An important thing to consider is the relative weighting of the two losses, namely,
where corresponds to the original loss above. Increasing towards leads to a an approximation that is accurate inside the domain but performs poorly on the boundaries. Similarly, leads to an approximation that is accurate on the boundary but poor inside the domain.
Implementation details and Code
Since most of the examples considered here involve a small number of training data points, the authors choose to exploit quasi-second order optimization methods such as L-BFGS. They do not consider mini-batching for the same reason and consider the full batch on the update. There are no theoretical guarantees on the existence of the minimizer but the authors observe empirically that as long as the PDE is well-posed the optimization algorithm converges to the correct solution.
The original implementation can be accessed at https://github.com/maziarraissi/PINNs which builds on top of Tensorflow. Corresponding PyTorch and Julia (Flux) implementations can be accessed at https://github.com/idrl-lab/idrlnet and https://neuralpde.sciml.ai/dev/
Examples: Schrodinger Equation
As a first example, consider a complex-valued differential equation (), namely the Schrodinger equation,
In order to generate the training data, the authors employ a classical pseudo-spectral solver in space () coupled with a high-order RK time stepper.
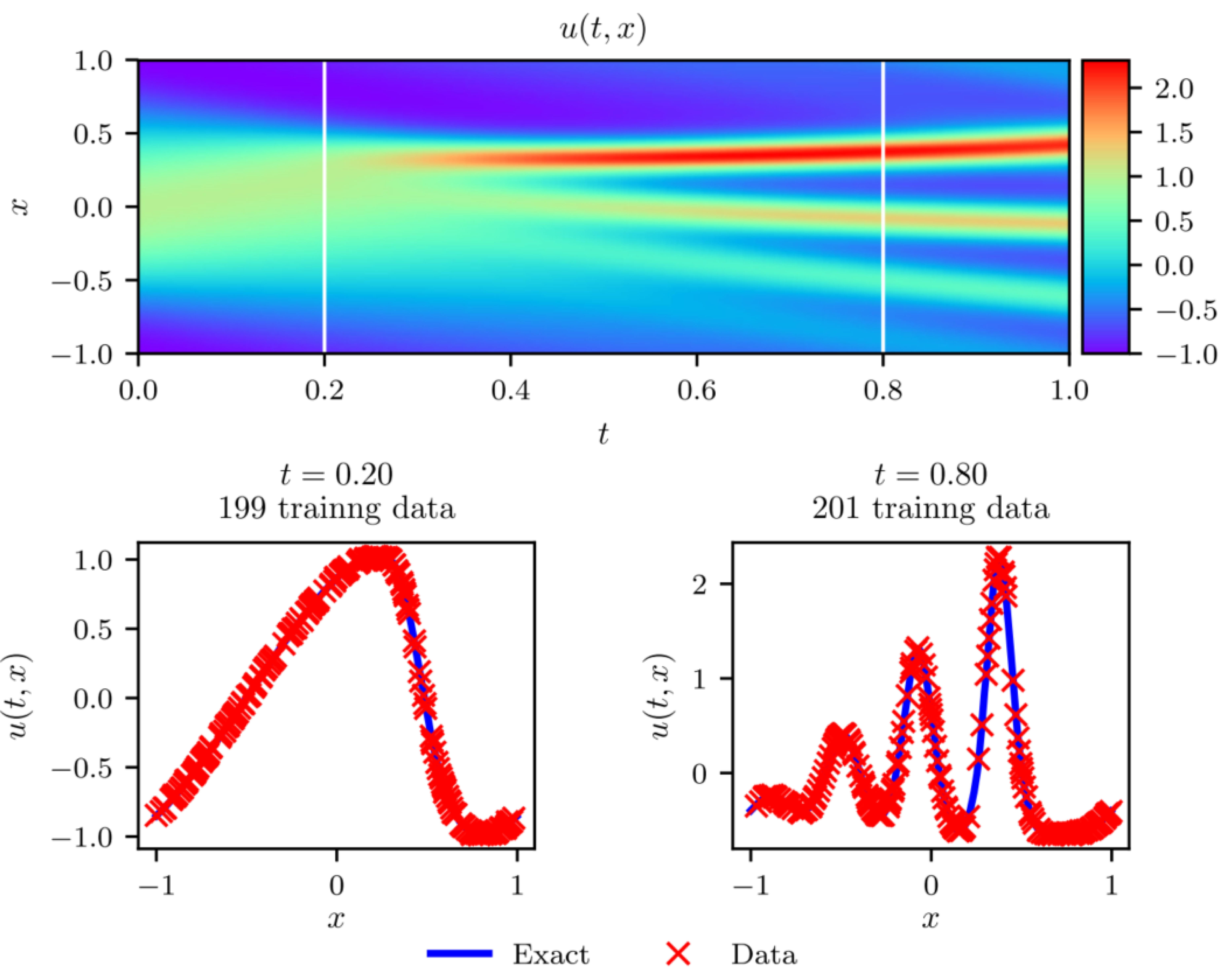
The results are shown in the figure below (Fig. 1 in the paper). PINN provides an accurate solution to Schrodinger equation and can handle periodic boundary conditions, nonlinearities and complex valued nature of the PDE efficiently.
Although PINN provides a good approximation to the solution above, training the network requires a large number of data points. This is where the adaptive time-stepping using RK methods comes into the picture. The authors propose an adaptive time-stepping with a neural net at each time-step. This significantly improves the approximation quality, and allows one to take much larger time-steps compared to traditional solvers.
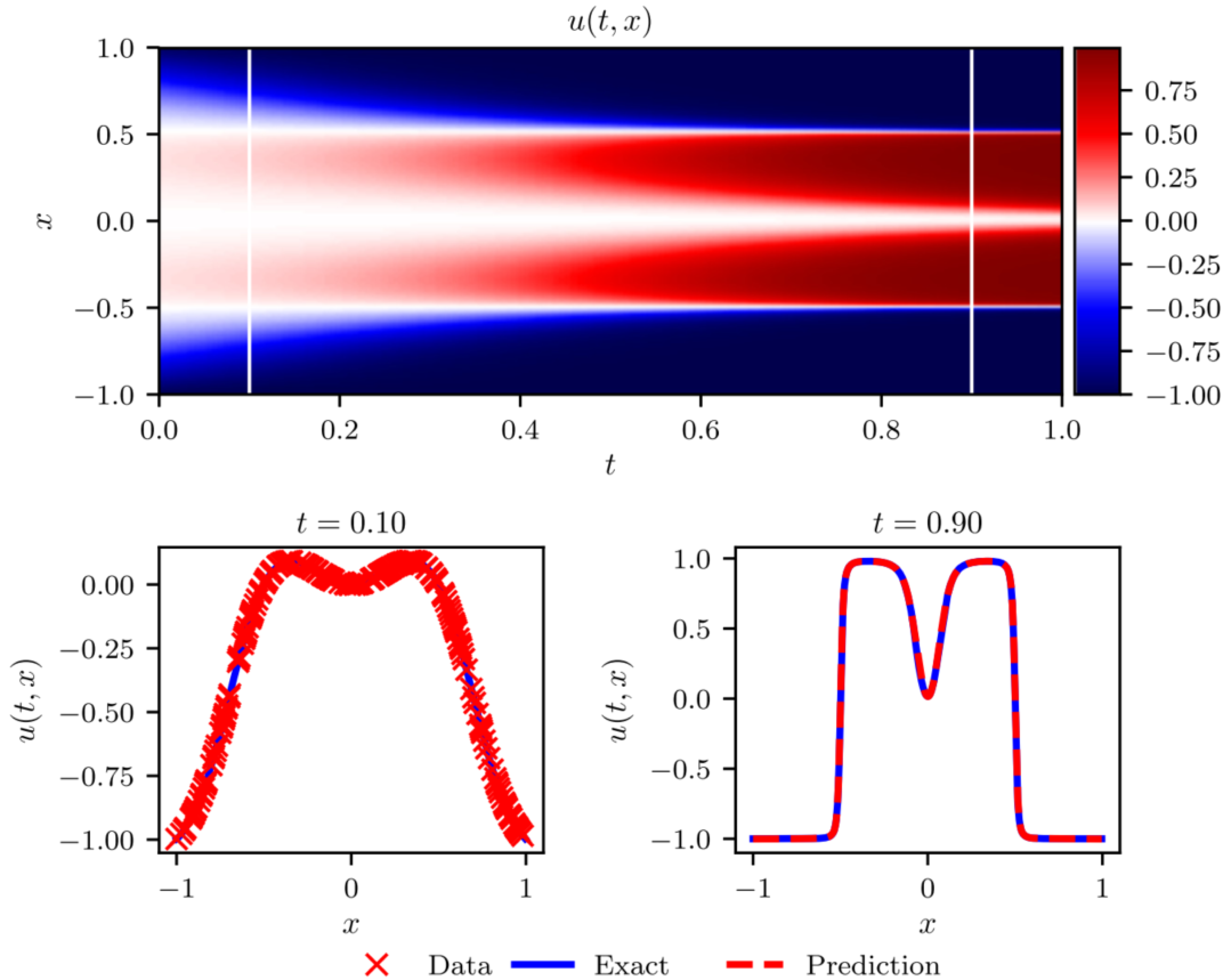
Examples: Allen-Cahn Equation
In order to test the adaptive time-stepping scheme, the authors next take a look at the Allen-Cahn equation.
The results show excellent agreement between the predicted and exact (numerical) solutions. The only difference here is that the authors consider the sum-of-squared errors as the loss function for training, instead of the MSE used before, i.e.
Examples: Navier-Stokes Equation
In this section, we take a look at how data-driven discovery of PDEs can be carried out using PINNs. Consider the NS equations in 2-dimensions,
- Here denotes the -component of the velocity, denotes the component and the pressure field.
- Conservation of mass requires
- Given a set of observations:
- The goal then is to learn , and pressure field by jointly approximating with a single NN with two outputs. The total loss function is given by
The training is carried out using a spectral solver NekTar and then randomly sampling points out of the grid for collocation. The figure on the bottom shows the locations of the training data-points.
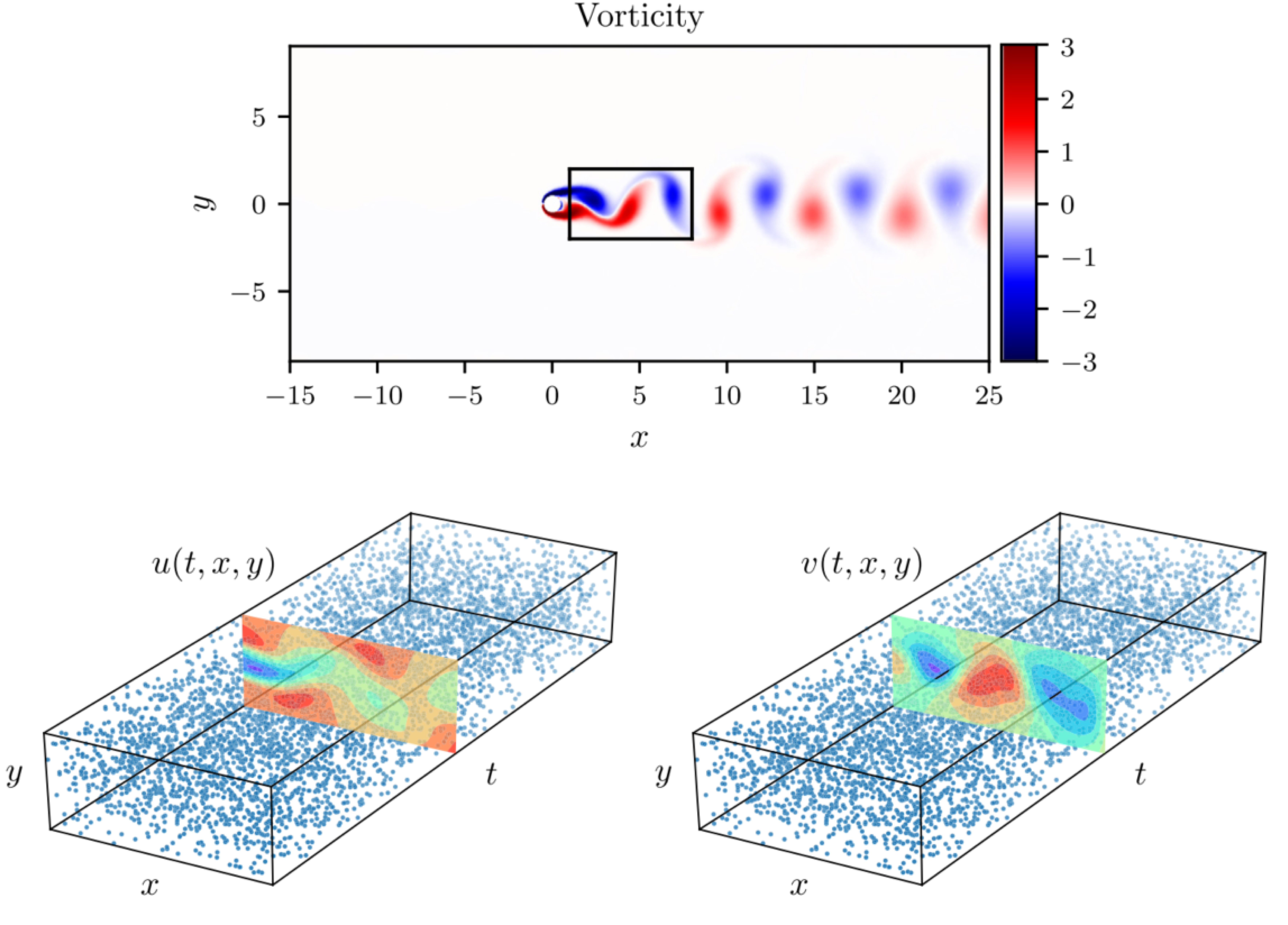
PINN is able to successfully predict the pressure field with just of the available data as collocation points as shown below (and also able to learn the parameters in the process)
Examples: KDv Equation
As a final example illustrating data-driven discovery of PDEs, the authors choose an equation with higher order derivatives, namely the Korteweg-de Vries equation, that is encountered in the modeling of shallow water waves,
The problem is to learn the parameters in a similar fashion as done for Navier-Stokes Equation
PINN again is able to learn the parameters to the desired accuracy and provide an accurate resolution of the dynamics of the system.
Conclusion
The major take-away of the paper can be summarized in the following concluding remarks.
- The authors introduced PINNs, a new class of universal function approximators that are capable of encoding any underlying physical laws that govern a given data-set (described by PDEs)
- They also prove a design for data-driven algorithms that can be used for inferring solutions to general nonlinear PDEs, and constructing computationally efficient physics-informed surrogate models.
They also rightly point to some lingering questions that still remain unanswered in the original paper:
- How deep/wide should the neural network be ? How much data is really needed ?
- Why does the algorithm converge to unique values for the parameters of the differential operators, i.e., why is the algorithm not suffering from local optima for the parameters of the differential operator?
- Does the network suffer from vanishing gradients for deeper architectures and higher order differential operators? Could this be mitigated by using different activation functions?
- Can we improve on initializing the network weights or normalizing the data? How about the choices for the loss function choices (MSE, SSE)? What about the robustness of these networks especially when applied to solve chaotic PDEs/ODEs?
References
-
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. M.Raissi, P.Perdikaris, G.E.Karniadakis
-
Physics Informed Deep Learning (Part I): Data-driven Solutions of Nonlinear Partial Differential Equations M.Raissi, P.Perdikaris, G.E.Karniadakis
-
Physics Informed Deep Learning (Part II): Data-driven Discovery of Nonlinear Partial Differential Equations M.Raissi, P.Perdikaris, G.E.Karniadakis