GAN2 Understanding Deep Convolutional Generative Adversarial Networks
Brandon Theodorou (bpt3@illinois.edu)
Today we will discuss the seminal Deep Convolutional Generative Adversarial Network (DCGAN) architecture as well as the paper and experiments by Alec Radford, Luke Metz, and Somit Chantal which introduced the architecture. DCGANs were representative of both the problems and promise of GANs during their early formulation, requiring tons of experimentation and tuning to properly train yet offering incredible and state of the art quality in terms of both their learned representation and image generation. The architecture worked wonderfully and continued to be used as the main GAN architecture for years after as additional innovations were built upon it. Hopefully this post allows you to understand DCGANs in terms of how they work and also the results they offered.
Background
GANs were first introduced by Goodfellow et al. and quickly caught on as an innovative yet powerful generative model. GANs are defined by a two player min-max game played between a pair of different trained models, typically parameterized as neural networks. These models are the Generator and the Discriminator. The Generator takes random noise and outputs a generated sample mirroring the desired data distribution, commonly an image. The Discriminator then takes samples, both real and fake, and attempts to predict whether they are real or not. In competing to be able to fool or correctly adjudicate one another, the models both improve until the Generator is able to output high quality images.
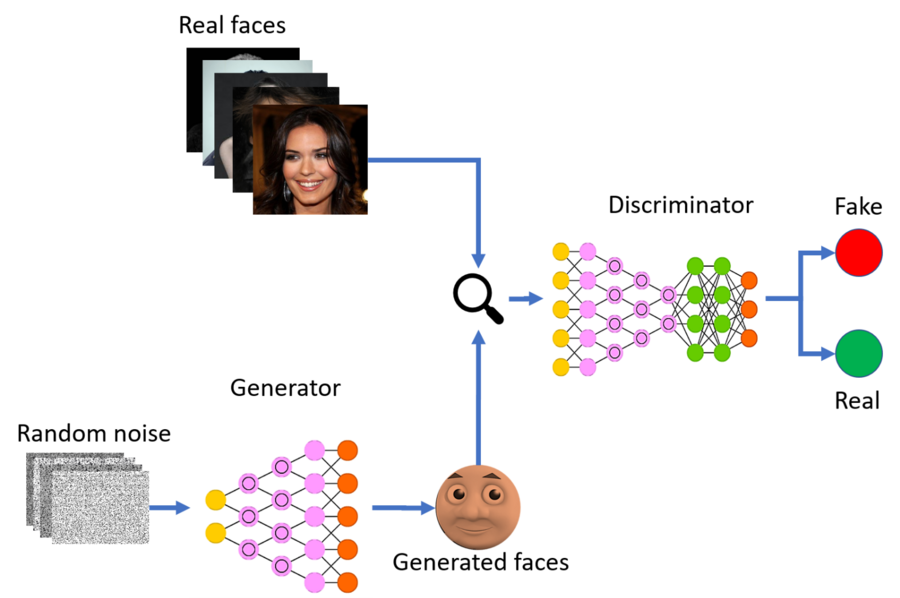
The DCGAN utilizes this training setup, offering a new architecture for the two models. In its framing during the presentation by Radford et al., the DCGAN lies at the intersection of two major and well studied fields of Artificial Intelligence, and it seeks the build upon both. The first is unsupervised representation learning, which seeks to learn strong representations of samples within a dataset in order to understand and manipulate the relevant traits as well as perform downstream tasks. At the point of time when the DCGAN was introduced, this topic was already considered important, but the leading models and algorithms such as k-means, autoencoders, ladder networks, and deep belief networks were still relatively unrefined compared to modern approaches. Similarly, the second field is that of generating natural images. This too was already considered important and well-researched but was not yet overly impressive as the produced images were wobbly and blurry across models such as VAEs, RNNs with deconvolutions, and even the existing GANs. While the DCGAN did not jump all the way to modern quality in the two fields, it succeeded in taking a large step forward in both.
The Architecture
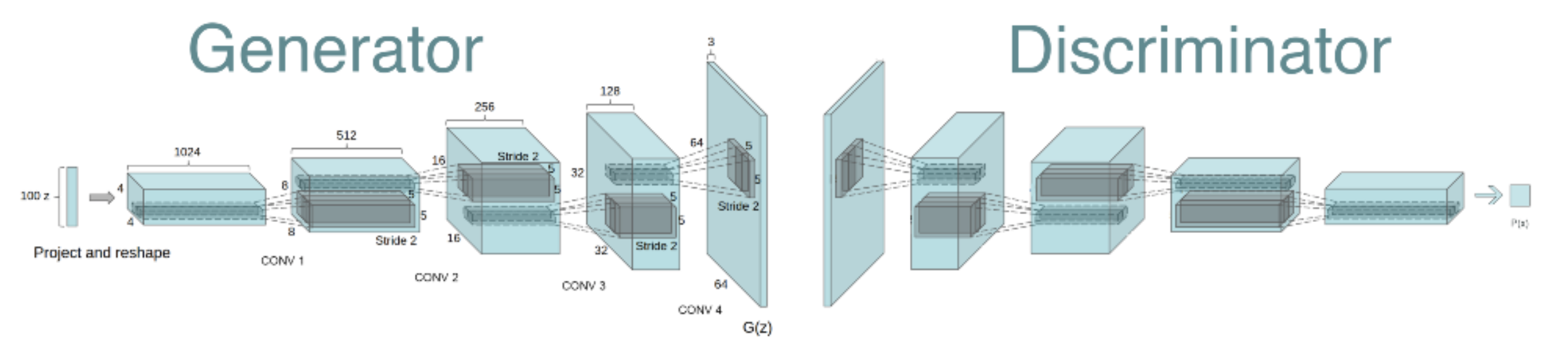
Up to this point, while GANs were undoubtedly an exciting architecture and idea, they had failed to consistently produce crisp output quality and were falling victim to a phenomenom termed mode collapse in which they produced a limited number of strong samples instead of a diverse representation of the entire distribution. Numerous papers including the introduction of Conditional GANs by Mirza and Osindero, a laplacian pyramid extension to GANs by Denton et al., a reccurent approach by Gregor et al., and a deconvolutional approach by Dosovitskiy et al. all were promising but struggled with either blurry or homogenous generation of natural images. A specific problem believed to be underlying these issues was that GANs were yet to successfully use the network most commonly used for image related tasks, CNNs. DCGANs fixed many of the downstream issues by addressing that underlying issue and utilizing CNNs as the core of their architecture, and they achieved that via a ton of experimentation and variation before settling on the following 4 innovations.
- Eliminating Pooling Layers: Most CNN-based architectures at the time utilized maxpooling or simple repetition to downscaling and upscaling their representations to different sizes throughout the architecture. However, the DCGAN architecture utilized only strided convolutions and fractionally-strided convolutions for the same purpose in order to allow the network to learn its own upscaling and downscaling algorithms.
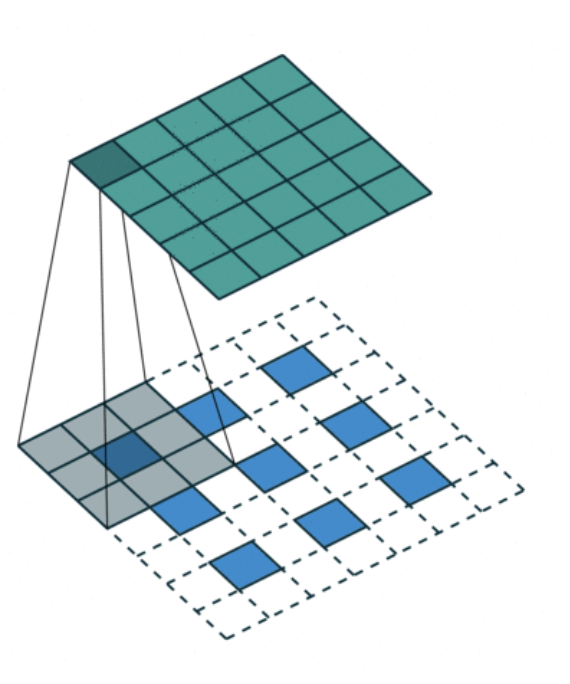
- Removing Fully Connected Layers: Most CNN-based architectures at the time also typically utilized fully connected layers as a head on top of their CNN model or otherwise within the model mixed into other blocks. However, the DCGAN eliminated as many such layers as possible, leaving only a single matrix multiplication at the start of the Generator to reshape the noise vector as well as a single sigmoid layer at the end of the Discriminator.
- Using Batch Normalization: The DCGAN also utilized the recently introduced batch normalization layer throughout their architecture. BatchNorm layers normalize the input to each layer which comes after them to be centered at zero and have unit variance in order to stabilize training and aid in gradient flow. They found that this helped with the problem of mode collapse and so applied it to all but the last Generator layer and first Discriminator layer.
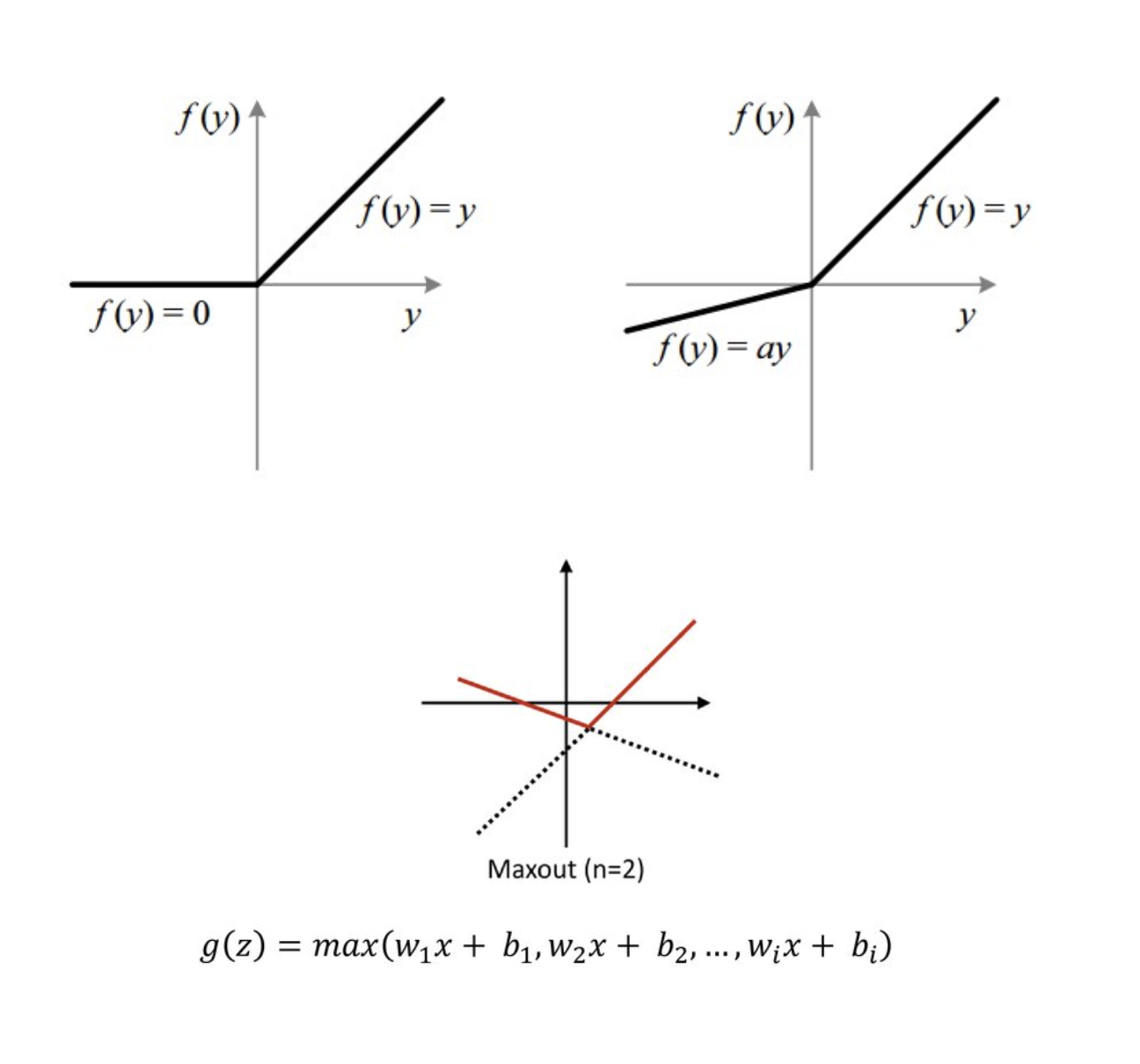
- Adjusting the Activation Functions: The final augmentation or novelty offered by the DCGAN was finely tuned activation functions. They used Tanh for the Generator output, ReLU for the other Generator layers, and LeakyReLU throughout the Discriminator. This contrasted with the previously used Maxout for other GANs.
These simple innovations were the result of a large amount of experimentation and combined to form the “all-CNN” DCGAN architecture which was able to stabilize training and improve both the generative capacity and also the learned representations.
Experiments
Upon arriving at their final DCGAN architecture, Goodfellow et al. continued to explore its power and effectiveness via a series of innovative and often fun experiments. The highlights of those experiments are described below.
Analysis of Possible Memorization
First, the authors were concerned that given the power of their DCGAN architecture, their trained models might just be memorizing the training data. So, they performed a number of experiments and analyses to ensure and argue that they were not. First, they trained for a single epoch with a small learning rate before qualitatively looking at the already strong generative samples and making the argument that the model could not be memorizing data yet and so must instead be learning. Similarly, they built a simple hashing model in order to match images to more quantitatively show that their generated images do not match images in the training dataset. So, the authors concluded that their model was learning rather than memorizing.
Using Learned Feature for Supervised Learning
They then continued to explore what exactly it was that their model was learning. They set up an experiment on both the CIFAR-10 and Street View House Numbers datasets in which they fully trained a DCGAN, extracted each of the Discriminator features maxpooled into a 4x4 representation, flattened, and concatenated, and finally trained a linear model on top of it for supervised classification. They then compared the results of the classification task as a proxy for the quality of the underlying representation, achieving near state of the art results on CIFAR-10 (and beating what they characterized as a strong k-means benchmark) and setting the new state of the art for the SVHN dataset.

Exploring the Latent Space
Next, they explored the latent space by picking 10 pairs of points for the original noise vectors and generating outputs at a series of points along the line connecting each pair. They found that generations shifted steadily from one image to another while remaining semantically sound, demonstrating a strong underlying representation as well as no signs of memorization (which would likely yield sharp jumps from one image to another).

Removing Features in Generations
Next, using manual analysis and a logistic regression model, the authors identified the features which corresponded to windows in the LSUN bedroom dataset. Then, during forward passes they dropped all positive values from these features and replaced them with noise, seeing how it affected the final generations. They impressively found that while the generations did suffer and get blurrier, they remained semantically sound and crucially did not contain any windows, instead typically replacing them with walls or mirrors.

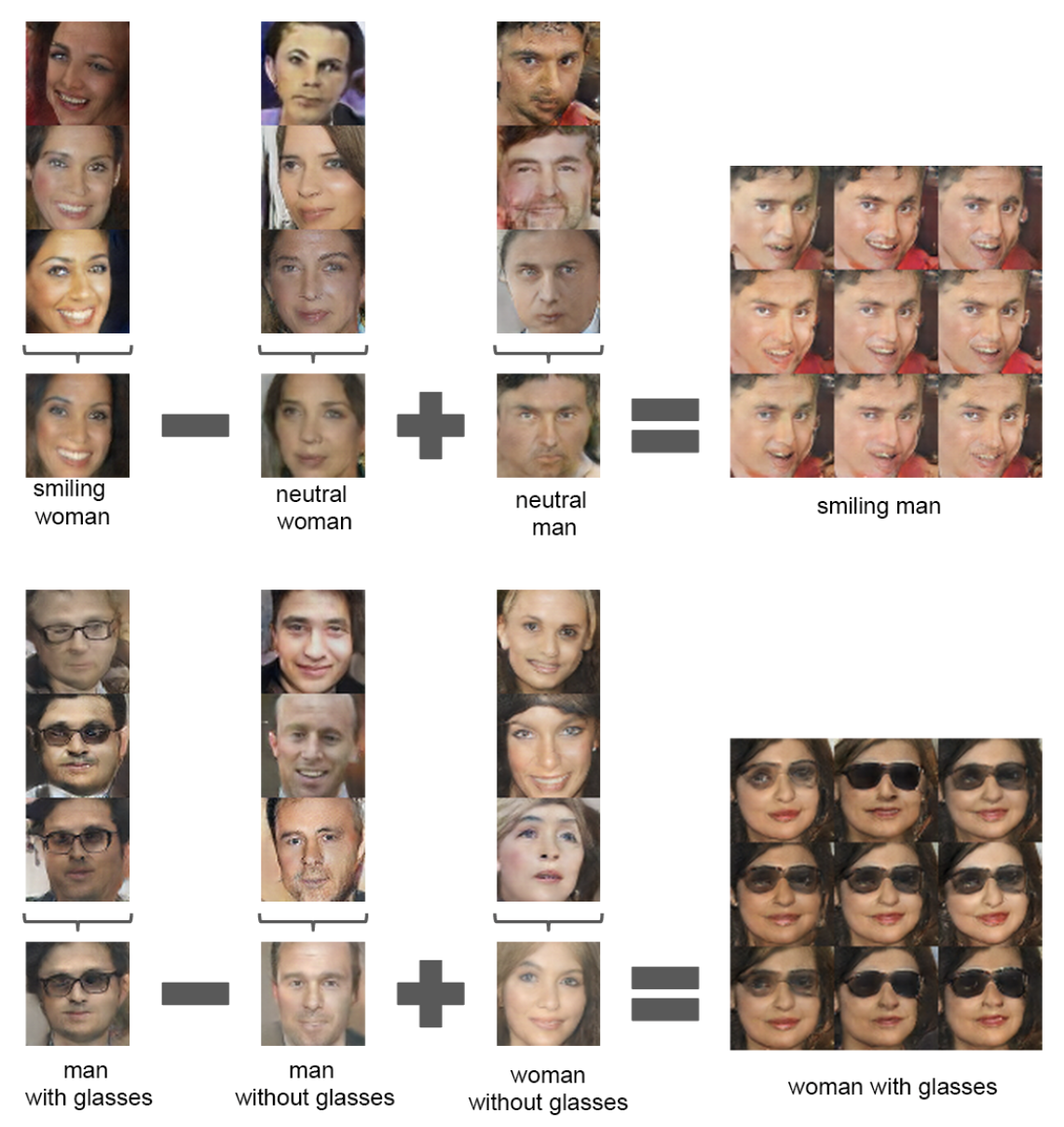
Performing Vector Arithmetic
Finally, the authors also performed vector arithmetic within the latent space. Instead of using a single point, they averaged points three or four points which shared a desired characteristic and then operated over that as the representation of the characteristic. In the model of the famous Word2Vec example in which the vector representation for King minus the representation for Man plus that for Woman is extremely close to Queen’s representation, they were able to similarly perform constructions to create a smiling man, woman with glasses, and a vector which represented faces turned at a variety of angles.
Wrapping Up
So, we have described the field and landscape that the DCGAN entered into, the core features and novelties of the architecture, and the series of experiments which explored and characterized its abilities. We have seen that it was a fairly simple architecture that did not introduce any complex or even novel innovations but rather iterated on many different innovations present in the literature of the day until finding an extremely effective combination and architecture. In doing so, they arrived at the DCGAN which was able to stabilize training and produce a wide array of crisp, realistic images on a variety of datasets as well as learn a strong underlying image representation.
Reference
Radford, A., Metz, L., and Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. In Proceedings of the International Conference on Learning Representations (ICLR), 2016.