GAN3 TOWARDS PRINCIPLED METHODS FOR TRAINING GENERATIVE ADVERSARIAL NETWORKS
Hantao Zhang (hantaoz3@illinois.edu)
Introduction
Background
Generative Adversarial Networks (GANs) have achieved great success at generating realistic and sharp looking images. However, they still remain remarkably diffcult to train and most papers at that time dedicated to heuristically finding stable architecture. And there is little to no theory explaining the unstable behaviour of GAN training.
GAN Formulation
GAN in its original formulation, plays the following game:
It can be reformulated as:
$ = \mathbb E_{x\sim p_{data}}[\log D^G(x)]+\mathbb E{z\sim p_z}[\log(1-D^G(G(z)))]$
$ = \mathbb E{x\sim p_{data}}[\log D^G(x)]+\mathbb E{x\sim p_g}[\log(1-D^G(x))]$
$ = \mathbb E{x\sim p_{data}}[\log \frac{p_{data}(x)}{p_{data}(x)+p_g(x)}]+\mathbb E_{x\sim p_g}[\log \frac{p_g(x)}{p_{data}(x)+p_g(x)}]$
and this is called the virtual training criterion.
It can be shown that C(G) is equivalent to the following:
where JSD is the Jensen-Shannon divergence:
where is the ‘average’ distribution, with density .
To train a GAN, we first train the discriminator to optimal, which is maximizing:
and the optimal discriminator is obatined as:
Plug in the optimal discriminator to , we get:
So, minimizing as a function of gives the minimized Jensen-Shannon divergence when the discriminator is optimal.
In theory, we would first train discriminator as close to optimal as we can, then do gradient steps on , and alternating these two things to get our generator. \color{red} But this doesn’t work. In practice, as the discriminator gets better, the updates to the generator get consistently worse
Main Contribution
Based on the problem regarding GAN training, the authors proposed 4 questions to be answered:
- Why do updates get worse as the discriminator gets better? Both in the original and the new cost function.
- Why is GAN training massively unstable?
- Is the new cost function following a similar divergence to the JSD? If so, what are its properties?
- Is there a way to avoid some of these issues?
We first take a look at the source of instabilities
Sources of Instability
Discontinuity Conjecture
From the cost function and the optimal discriminator, we ‘know’ that the trained discriminator will have cost of at most . However, in practice, if we train D till convergence, its error will go to 0, pointing to the fact that the JSD between them is maxed out. The only way this can happen is if the distributions are not continuous, or they have disjoint supports. And one possible cause for the distribution to be discontinuous is if their supports lie on low dimensional manifolds. Previous work on GAN showed strong empirical and theoretical evidence to believe that is indeed extremely concentrated on a low dimensional manifold. And the authors proved that this is the case as well for .
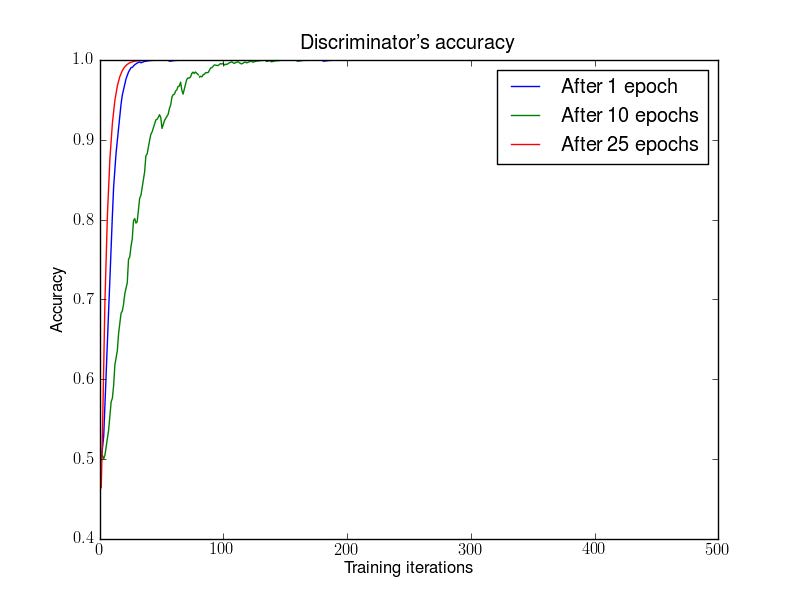
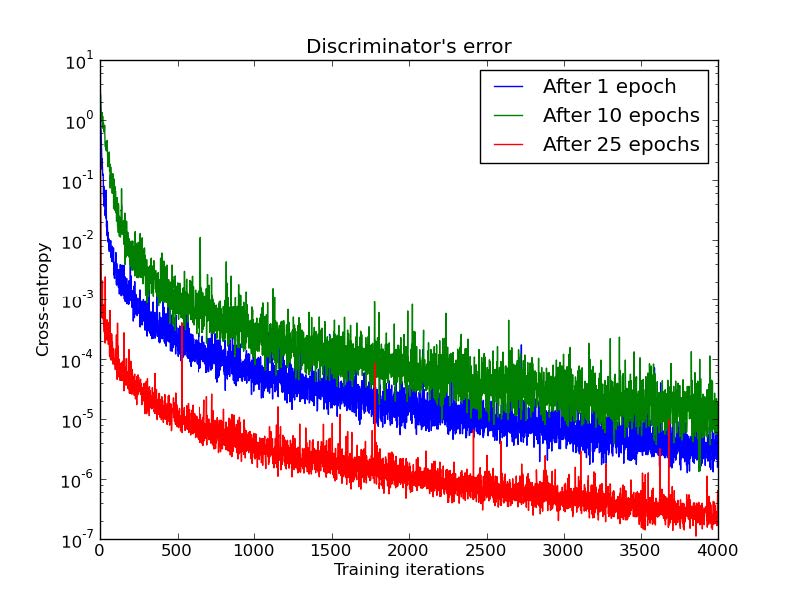
Below regards DCGAN trained for 1,10,25 epochs. Then, with generator fixed, train a discriminator from scratch.
Lemma 1
Let be a function composed by affine transformations and pointwise non-linearities, which can either be rectifiers, leaky rectifiers, or smooth strictly increasing functions (such as the sigmoid, tanh, softplus, etc). Then, is composed in a countable union of manifolds of dimension at most dim . Therefore, if the dimension of is less than the one of , will be a set of measure 0 in .
The intuition behind this lemma is is defined via sampling from a simple prior , and then applying a function , so the support of has to be contained in . If the dimensionality of is less than the dimension of , then it’s impossible for to be continuous.
Perfect Discrimination Theorem
Theorem 2.1
If two distributions and have support contained on two disjoint compact subsets and respectively, then there is a smooth optimal discriminator that has accuracy 1 and .
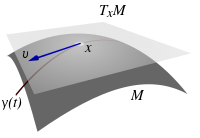
Definition (Transversal Intersection)
Let and be two boundary free regular submanifolds of , which in our case will simply be . Let be an intersection point of the two manifolds. We say that and intersect transversally in if , where means the tangent space of around .
![]()
Definition (Perfect Alignment)
We say that two manifolds without boundary and \textbf{perfectly align} if there exists such that and don’t intersect transversally in . And let and denote the boundary of manifolds and , we say and are perfectly align if any of the boundary free manifold pairs (, ), (, ), (, ),(, ) perfectly align.
Lemma 2
Let and be two regular submanifolds of that don’t have full dimension. Let be arbitrary independent continuous random variables. We therefore define the perturbed manifolds as and . Then [\mathbb P_{\eta, \eta’}(\mathcal{\tilde M} \text{ does not perfect align with }\mathcal{\tilde P}) = 1]
This implies that, in practice, we can safely assume that any two manifolds never perfectly assign, since arbitrarilly small perturbation on two manifolds will lead them to intersect transversally or don’t intersect at all.
Lemma 3
Let and be two regular submanifolds of that don’t perfectly align and don’t have full dimension. Let . If and don’t have boundary, then is also a manifold, and has strictly lower dimension than both the one of and the one of . If they have boundary, is a union of at most 4 strictly lower dimensional manifolds. In both cases, has measure 0 in both and .
If two manifolds don’t perfectly align, their intersection will be a finite union of manifolds with dimensions strictly lower than both the dimension of and .
Theorem 2.2 (The Perfect Discrimination Theorem)
Let and be two distributions that have support contained in two closed manifolds and that don’t perfectly align and don’t have full dimension. We further assume that and are continuous in their respective manifolds, meaning that if there is a set A with measure 0 in , then (and analogously for ). \color{red} Then, there exists an optimal discriminator that has accuracy 1 and for almost any x in or , is smooth in a neighbourhood of and .
Combining the two theorems (2.1 and 2.2) stated together tells us that there are perfect discriminators which are smooth and constant almost everywhere in and . And the fact that the discriminator is constant in both manifolds points to the fact that we won’t be able to learn anything by backproping through it.
Theorem 2.3
Let and be two distributions whose support lies in two manifolds and that don’t have full dimension and don’t perfectly align.
We further assume that and are continuous in their respective manifolds. Then,
This implies:
- divergences will be maxed out even if the two manifolds lie arbitrarilly close to each other (impossible to apply gradient descent)
- samples of our generator might look impressively good, yet both KL divergences will be infinity
- attempting to use divergences out of the box to test similarities between the distributions we typically consider might be a terrible idea
Vanishing Gradients on the Generator
Denote
(Note: The authors stated that this norm is used to make proofs simpler, and can be replaced with Sobolev norm for covered by the universal approximation theorem in the sense that we can guarantee a neural network approximation in this norm)
Theorem 2.4
Let be a differentiable function that induces a distribution . Let be the real data distribution. Let D be a differentiable discriminator. If the conditions of Theorem 2.1 and 2.2 are satisfied, , and , then
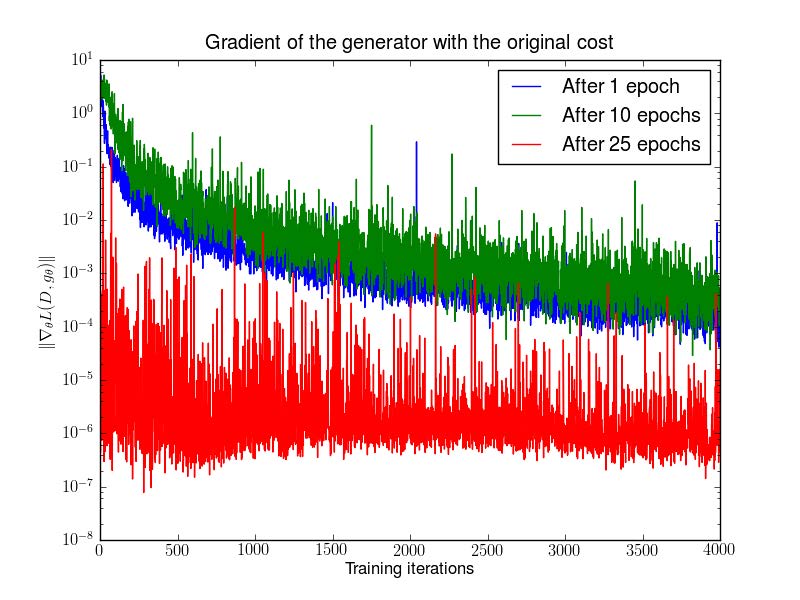
Theorem 2.4 shows that as our discriminator gets better, the gradient of the generator vanishes.
And the figure below shows an experimental verfication of the above statement. First train a DCGAN for 1, 10 and 25 epochs. Then, with the generator fixed train a discriminator from scratch and measure gradients with the original cost function.
The Alternative
In original GAN paper, the authors conjectured that the instable behaviour is because of the choose of loss function so they proposed an alternative to “fix” it, but even with the alternative loss function, the problem remains, and yet little is known about the nature of the alternative loss.
To avoid vanishing gradient when the discrminator is very confident, an alternative gradient step for the generator is used:
Theorem 2.5
Let and be two continuous distributions, with densities respectively. Let be the optimal discriminator, fixed for a value . Therefore,
Theorem 2.6
Let be a differentiable function that induces a distribution . Let be the real data distribution, with either conditions of Theorems 2.1 and 2.2 satisfied. Let D be a discriminator such that is a centered Gaussian process indexed by and independent for every and another independent centered Gaussian process indexed by and independent of every . Then, each coordinate of
is centered Cauchy distribution with infinite expectation and variance.
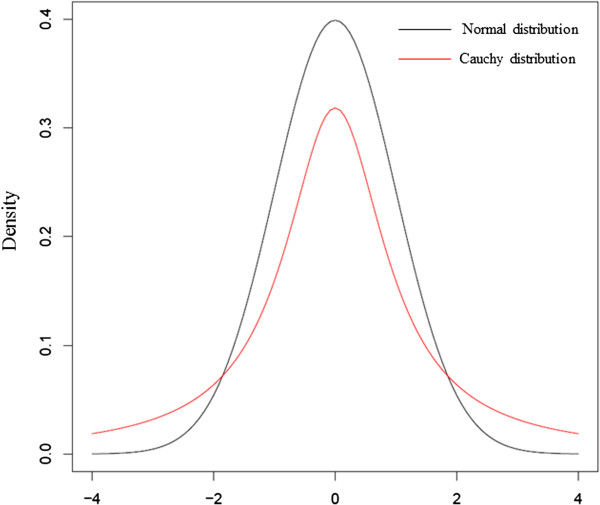
Theorem 2.6 implies that we would have large variance in gradients, and the instable update would actually lower sample quality. Moreover, the fact that the distribution updates are centered means that, if we bound the updates, the expected update would be 0, providing no feedback to the gradient.
Towards Softer Metrics and Distributions
Break Assumptions
To fix the Instability and vanishing gradients issue, we need to break the assumptions of previous theorems. And the authors choose to add continuous noise to the inputs of the discriminator, therefore, smoothening the distribution of the probability mass.
Theorem 3.1
If X has distribution with support on and is an absolutely continuous random variable with density , then is absolutely continuous with density
$ = \int_{\mathcal M}P_\epsilon(x-y)d\mathbb P_X(y)$
Theorem 3.2
Let and be two distributions with support on and respectively, with . Then, the gradient passed to the generator has the form
This theorem proves that we will drive our samples towards points along the data manifold, weighted by their probability and the distance from our samples.
To protect the discriminator from measure 0 adversarial examples, it is important to backprop through noisy samples in the generator as well.
Corollary
Let and , then
$ = \mathbb E_{z\sim p(z)}[a(z)\int_{\mathcal M}P_\epsilon(\tilde g_\theta(z)-y)\nabla_\theta||\tilde g_\theta(z)-y||^2d\mathbb P_r(y)-b(z)\int_{\mathcal P}P_\epsilon(\tilde g_\theta(z)-y)\nabla_\theta||\tilde g_\theta(z)-y||^2d\mathbb P_g(y)]$
Wasserstein Metric
The other way to go is to use Wasserstein Metric to replace traditional JSD distance.
Definition
[W(P,Q)=\inf_{\gamma\in\Gamma}\int_{\mathcal X\times\mathcal X}||x-y||_2d\gamma(x,y)] where is the set of all possible joints on that have marginals P and Q.
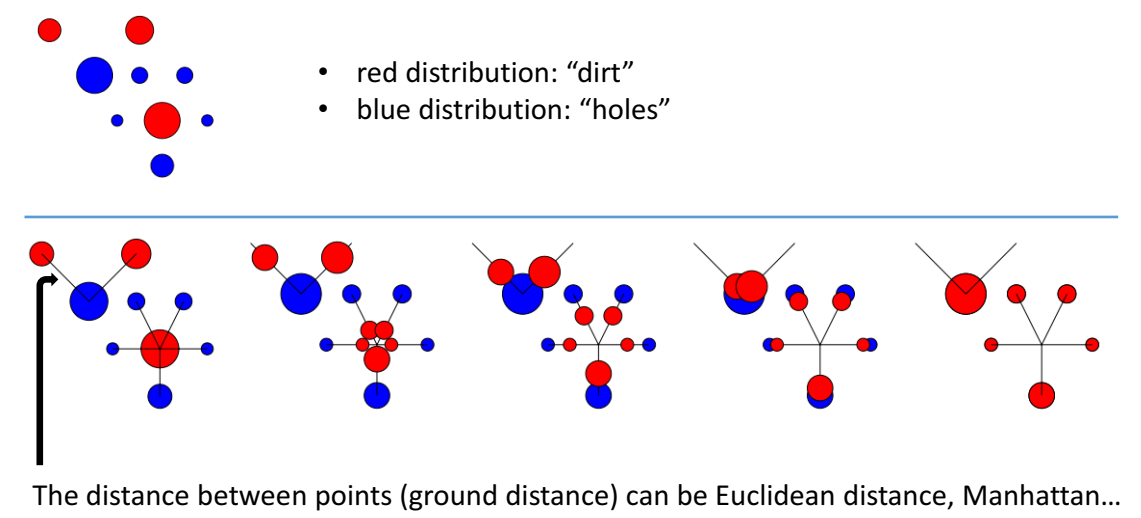
Wasserstein Distance is also called Earth Mover’s Distance (EMD), it’s the minimum cost of transporting the whole probability mass of P from its support to match the probability mass of Q on Q’s support.
Intuitively, given two distributions, one can be seen as a mass of earth properly spread in space, the other as a collection of holes in that same space. Then, the EMD measures the least amount of work needed to fill the holes with earth. Here, a unit of work corresponds to transporting a unit of earth by a unit of ground distance.
Lemma 4
Let be a random vector with mean 0, then we have
where is the variance of .
Theorem 3.3
Let and be any two distributions, and be a random vector with mean 0 and variance V. If and have support contained on a ball of diameter C, then
This theorem implies that Wasserstein Distance can be controlled since both parts of this upper bound can be manually controlled.