GAN5 Understanding the Connection Between Privacy and Generalization in Generative Adversarial Networks
Brandon Theodorou (bpt3@illinois.edu)
Today we will discuss the connection between privacy and generalization as applied towards GANs as was introduced by the paper Generalization in Generative Adversarial Networks: A Novel Perspective from Privacy Protection by Bingzhe Wu, Shiwan Zhao, ChaoChao Chen, Haoyang Xu, Li Wang, Xiaolu Zhang, Guangyu Sun, and Jun Zhou. While relatively simple in both its theoretical and experimental contributions, the paper is nonetheless thought provoking and offers an interesting and important perspective relating these two important ideas. Hopefully this post characterizes those contributions and is able to introduce you to the concepts of privacy and generalization as well as their connection.
Background
GANs were first introduced by Goodfellow et al. and quickly grew in popularity as a powerful generative model. They are defined by a two player min-max game played between the Generator and the Discriminator models, which are typically parameterized as neural networks. The Generator takes random noise and outputs samples mirroring the desired data distribution, typically an image. The Discriminator then takes samples, both real and fake, and attempts to predict whether or not they are real. In competing to be able to fool or correctly adjudicate one another, the models both improve until the Generator is able to output high quality images.
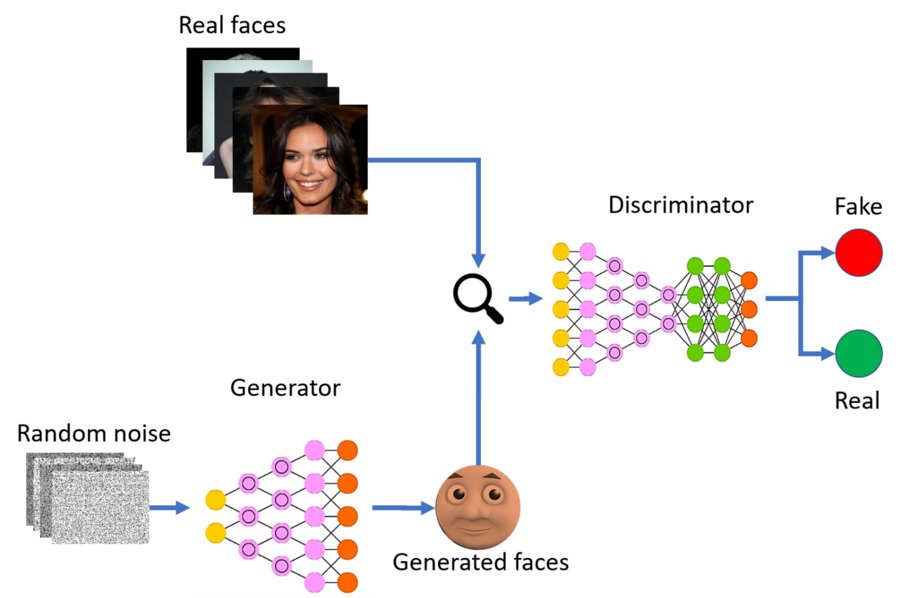
At the point of time where this paper was released, GANs were already well-studied and achieving impressive state of the art results in image generation among other applications. One main focuses of research in the field at the time was regarding attempts at addressing regularization of GAN training for the purpose of better generalization. This work fell into two main paths addressed by the authors as relevant to their work. The first is Lipschitz regularization which seeks to make the Discriminator Lipschitz continuous through methods such as gradient clipping, gradient penalties, or spectral regularization. The second is the relatively new Bayesian GAN trained using Bayesian learning. Each of these methods had been recently introduced and showed improvements in performance and generalization, and these authors explored why from the novel perspective of privacy.
The Motivation
The paper was motivated by the simple realization that both reducing the generalization gap and protecting the individual’s privacy are achieved in the same way. They both share the same goal of encouraging a neural network to learn the features of the underlying distribution rather than memorizing the features of each individual. So, the paper builds on that connection and explores it both theoretically and empirically.
Theoretical Analysis
The authors perform their theoretical analyses not on a specific architecture or objective but rather the learning algorithms for the Discriminator and Generator, and , as a whole. Specifically, in the context of GAN training, they analyze which maximizes and which minimizes , defining the characteristic min-max game.
However, while and nominally optimize over and , the analysis stems from the fact that they in practice do not. The true data distribution is intractable, so a finite training dataset is used instead. Thus, and actually optimize over the empirical losses and . Since doesn’t actually touch the training data (it is just the noise passed into the Generator), the analysis then simply considers optimizing given a fixed Generator where they seek to understand the generalization gap which is how much worse the Discriminator performs due to using the empirical distribution and loss rather than the true underlying values.
With the GAN and generalization definitions formulated, the only remaining piece neccessary before moving into the theoretical analyses are a couple of definitions regarding privacy. The first is differential privacy. Formally, A randomized algorithm satisfies -differential privacy if for any two adjacent datasets (datasets with a single datum switched) D and for any subset of outputs it holds: which basically means that a single data point has negligible effect on the final weights and thus outputs of the model. The second is Uniform RO-Stability. A randomized algorithm is uniform RO-stable with respect to the discriminator loss function if for all adjacent datasets it holds that: which basically means that a small change to the input yields a constrained change to the output.
Now we are finally ready to build the theoretical results. The authors use two lemmas from previous literature to build two theorems of their own. The two lemmas state that differential privacy entails Uniform RO-Stability and that Uniform RO-Stability entails a bounded generalization gap (with each of the three concepts coming with their own bound within the lemmas). The author’s first theorem then simply connects the two lemmas to state that -differential privacy entails a data-independent bounding of the generalization gap. The second theorem states roughly the same idea in the context of GANs, showing that if is -differentially private, then the generalization gap of the discriminator outputted by the k-th iteration of can be bounded by a universal constant related to .
These theorems are relatively simple in building on existing principles and lemmas (and in fact both have proofs which are given in no more than seven lines), but they are nonetheless important and thought provoking. They demonstrate theoretically that privacy entails generalization, and they furthermore explain how recent techniques such as Lipschitz regularization and Bayesian learning are so successful in producing more generalizable results as they are previously known to be important and effective factors in producing algorithms with strong privacy guarantees.
Quantitative Experiments
Upon arriving at their theoretical results showing that privacy entails generalization, the authors continued to perform a number of experiments showing that generalization generally correlates in the other direction back to privacy. They did so by performing membership attacks based on a variety of differently trained GAN models.
Membership Attacks
A membership attack is an attempt to determine whether a given piece of data is from the original training set that a model is trained. The attacker can either have access to the model in question itself or a series of results that they use to build a proxy network, and the authors tested both such variants.
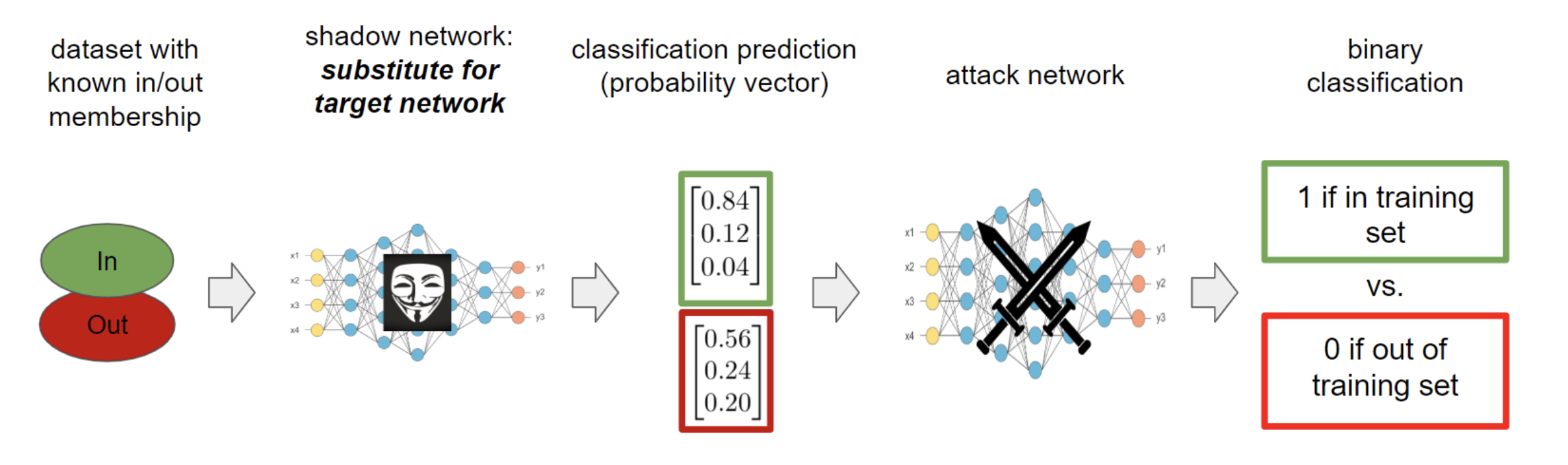
Experimental Setup
The authors carried out their membership attack setup on two different datasets, Labeled Faces in the Wild and Invasive Ductal Carcinoma image. They trained a variety of different GAN algorithms (both regularized and normal) within the DCGAN architecture. They then created attack datasets by randomly picking samples mixing the original training and testing datasets. Finally, they created a very simple attacker model which for a given data point outputs that the datapoint is in the training dataset if the discriminator (or proxy) model outputs a greater than average value when given the data point.
Experimental Results
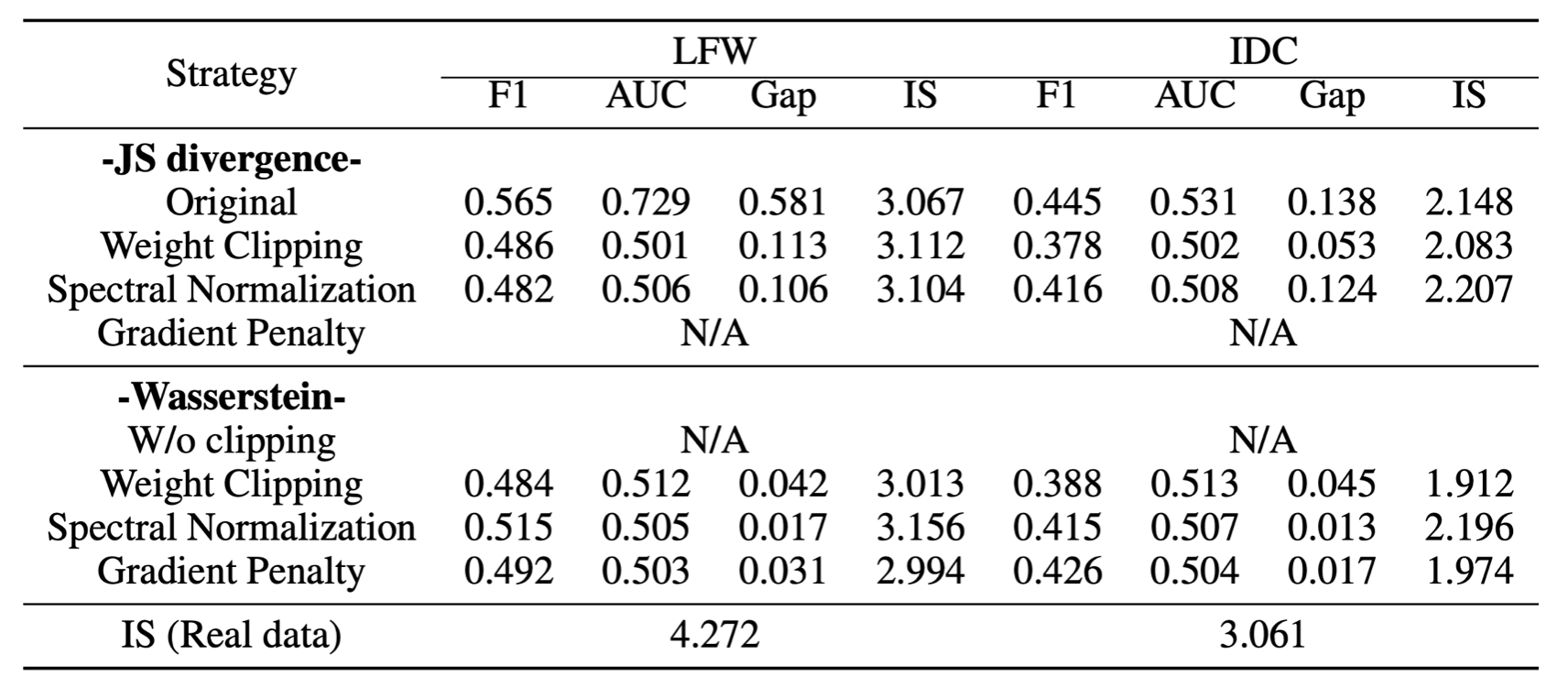
The authors found that GANs which generalized better by containing some form of regularization were also more effective at impeding the performance of the attacker and so offered additional levels of privacy. In their findings there was a clear divide between the original GAN algorithm and all others (which each offered some form of regularization across both the original JS Divergence and the Wasserstein objectives) in terms of the original GAN having both a much larger generalization gap and also much higher metrics of F1 and AUC scores measuring the effectiveness of the membership attack. Specifically, in the experiment on the Labeled Faces in the Wild dataset assuming that the attacker has full access to the Dicriminator model, the attacker achieves an F1 score of 0.565 and AUC of 0.729 for the original GAN while only 0.515 and 0.512 for the next closest models, the Wasserstein GANs with Spectral Normalization and Weight Clipping respectively. Similarly, the generalization gap for the original GAN 0.581, and it is 0.113 for the next closest model, the Weight Clipping model with the original GAN objective. The table below gives the full results for both experiments in which the attacker had access to the full Discriminator model, and similar results were seen in the “black-box” attack setup in which they only had downstream results with which to build a proxy model. So, the experiment backed up the idea that more generalizable GANs are more effective at protecting the privacy of the original dataset.
Wrapping Up
So, we have explored the new perspective offered by our authors on the topic of GAN generalization through the lens of privacy. We have shown that the connection between privacy is concrete and direct through a series of theorems demonstrating that privacy entails generalization, and we have shown that the connection holds quantitatively as well through the results of a series of membership attack experiments. While both the theoretical and experimental results are fairly simple, the insight and perspective is a valuable one, connecting the two very important topics and directing future work towards solving both problems.
Reference
Wu, B., Zhao, S., Xu, H., Chen, C., Wang, L., Zhang, X., Sun, G., and Zhou, J. Generalization in Generative Adversarial Netwokrs: A Novel Perspective from Privacy Protection. NeurIPS, 2019.