VAE1 Importance Weighted Autoencoders
Shengyu Feng (shengyu8@illinois.edu)
Importance Weighted Autoencoders: what makes a good ELBO in VAE?
Variational AutoEncoders (VAE) [1] is a powerful generative model which combines the variational inference and autoencoders together. It approximates the posterior distribution with a simple and tractable one, and optimize the lower bound of the true data distribution, which is called evidence lower bound (ELBO). Althoug optimizing ELBO is effective in practice, this estimation is actually biased, and it’s shown that this bias actually cannot be eliminated in vanilla VAE. Here we introduce a work that tries to minimize this bias called Importance Weighted Autoencoders (IWAE) [2], along with its variants which combines the objective in VAE and IWAE.
Introduction to VAE and ELBO
VAE consists of the encoder and the decoder . It first encodes each sample into a distribution of the latent variables . Then the latent variables are sampled from the distibution as . The latent variables serve as the input to the decoder where the reconstructed output is . The overview of VAE is shown in Fig 1.

The training objective of VAE is to maximize ELBO. There are multiple ways to derivate ELBO, and one way is through the Bayesian theory. can be rewritten as
Here the second term in Equation (4) is actually the the KL divergence that is always non-negative. Therefore, the first term actually serve as an lower-bound of , which is exactly the ELBO. Furthermore, ELBO can be written in the regularized reconstruction form as
where the first term regularizes the posterior distribution towards the prior which is usually set as a standard normal distribution, and the second term corresponds to the reconstruction.
Nonetheloss, the regularization term actually has a conflict with the second term in Equation (4). When the regularization term is perfectly optimized, will stay close to the prior , meanwhile, it makes hard for to be close enough to the true posterior distribution . Therefore, the gap between ELBO and the true data distribution, namely , will always exists, which prevents ELBO from being a tighter lower bound.
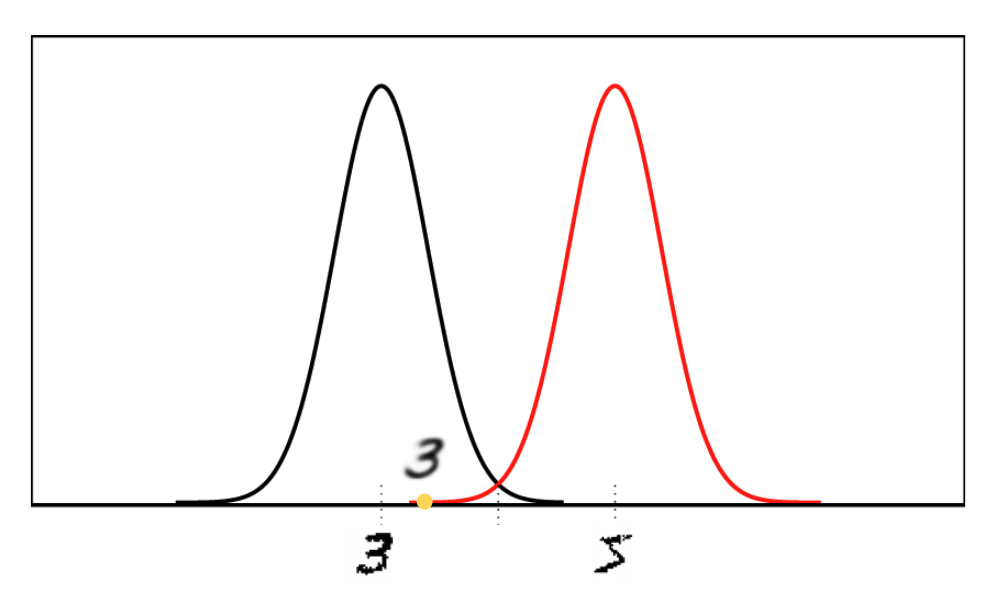
We can understand this in the other view. When a latent variable is sampled from the low-probability region of a latent distribution, it would inevitably lead to a bad reconstruction.
For the example in Fig 2, if we unfortunately sample a latent variable from the distribution of digit “5” (red) in the orange point, it turns out that this latent variable actually lies in the high probability region of the latent distribution generated by digit “3” (black) and it’s highly possible that we get a final reconstruction more similar to “3” rather than “5”. To make the posterior distribution close to the normal distribution, the regularizer will penalize this sample heavily by decreasing the variance, leading to a small spearout of the latent distribution. This drawback motivates the work of Importance Weight Autoencoders (IWAE) to introduce the importance weights into VAE, where a sampled latent variable which is far away from the mean will get assigned a lower weight during updates since it is known to give a bad reconstruction with high probability.
Importance Weighted Autoencoders
Another way to derivate ELBO is through the Jensen’s Inequality. Since is a concave function, we have
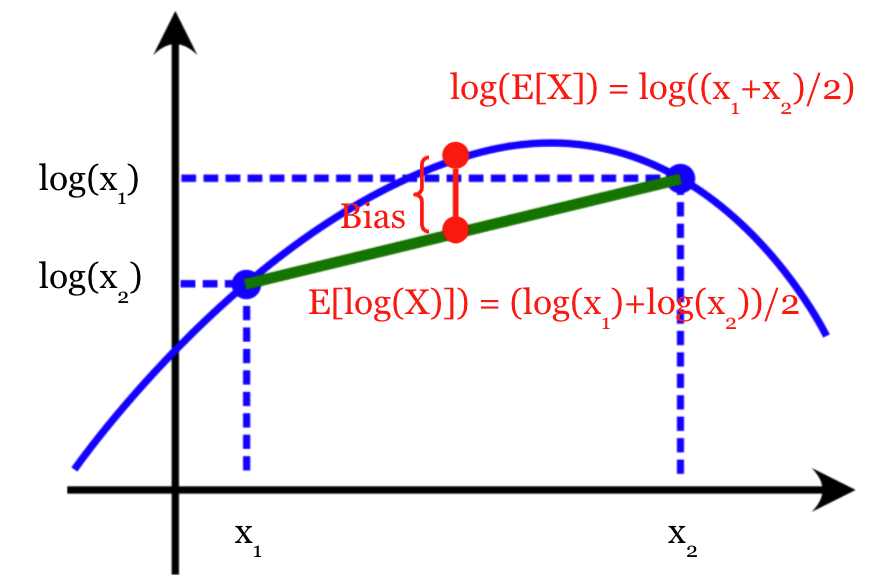
A simple example is shown in Fig 3. Consider a random variable taking value from , and we want to estimate . If we use to estimate it, then the estimation will converge at , and the bias term cannot be eliminated by simply increasing the sampling times.
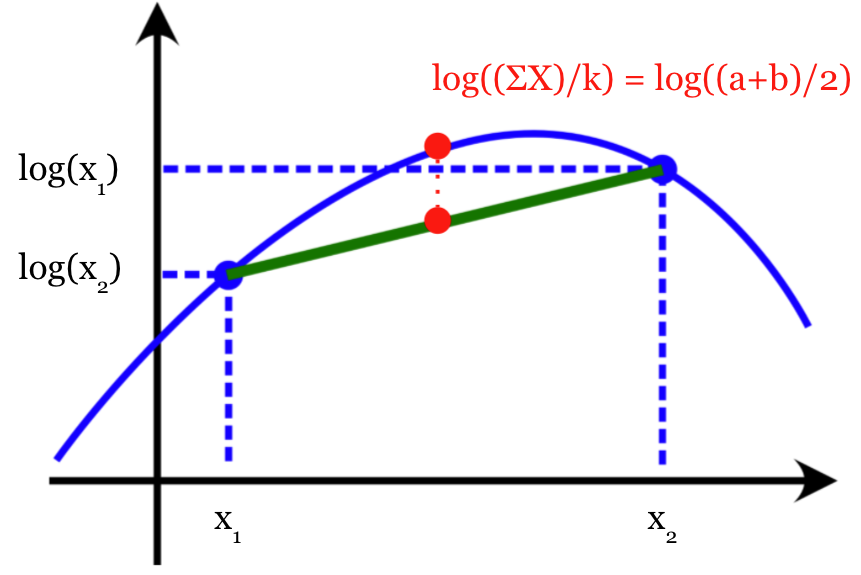
If we instead use for estimation, when we gradually increase the sampling times , the bias will become smaller. And when , the term inside the expectation actually becomes a constant which is exactly , as shown in Fig 4.
If we apply this property on ELBO estimation, let and , we actually have the theorem
And will converge to when is bounded.
Equipped with this theorem, IWAE simply replace sthe objective in VAE with , where . This gives a tighter lower bound compared with ELBO. And when , IWAE is reduced to VAE.
In the backward pass, the gradient of can be written as
where is the normalized importance weights, which makes the model name “Importance Weighted” Autoencoders. In VAE, takes the value .
The meaning of the importance weights could be interpreted as this: if a latent sample itself has low probability in the latent distribution, then it should get assigned a lower weight in the gradient update since it’s known to cause a bad reconstruction with high probability. Introducing importance weights can effectively lower the risk shown in Fig 2.
Variants of IWAE
To make a straightforward comparison with ELBO in VAE, we fix the sampling times for both VAE and IWAE as . The ELBO for IWAE and VAE become
The main difference here is the position of the average operation, either insider or outside . IWAE regards the sampling outside as the variance reduction, and it’s shown that IWAE actually doesn’t suffer from the large variance, so IWAE puts all sampling inside to reduce the bias as much as possible.
However, a follow-up work [3] of IWAE theoretically proves that the sampling outside is crucial to the training of the encoder. A tighter bound used by IWAE helps the generative network (decoder) but hurts the inference network (encoder).
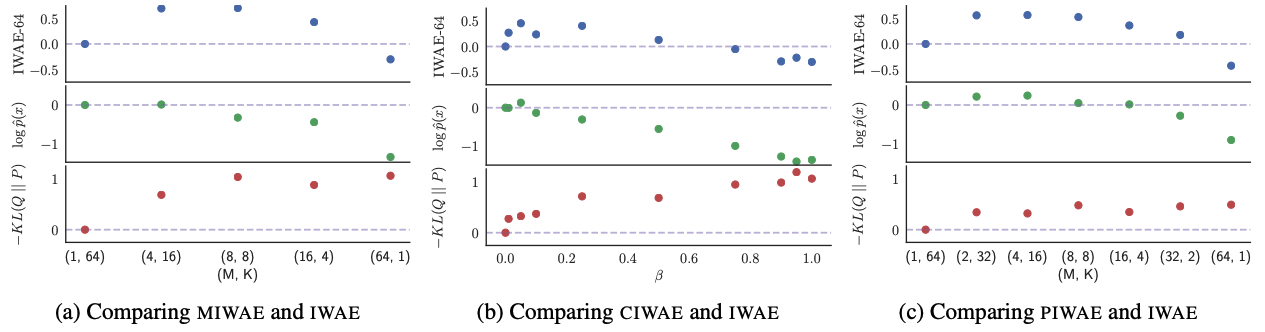
Based on this discovery, three new models combining and are proposed. For the following text, we fix the total sampling times to be , where is the sampling times outside and is the sampling times inside .
- MIWAE. MIWAE simply uses an ELBO objective with both and , i.e.,
- CIWAE. CIWAE uses a convex combination of two ELBOs, i.e.,
- PIWAE. PIWAE uses different objectives for the inference network and generative network. For the generative network, it keeps the objective of IWAE, . While for the inference network, it switches to the objective .
Experimental Results
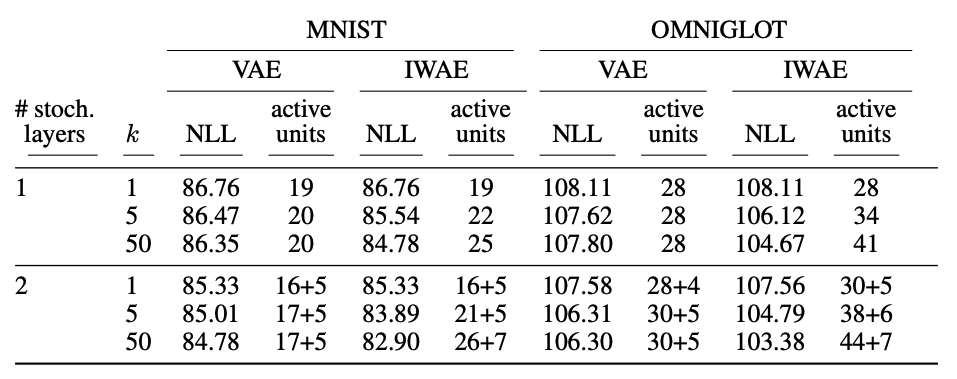
The experimental results demonstrate the advantage of IWAE against VAE as Table 1 shows. IWAE achieves lower negative log-likelihood (NLL) and more active units (active units captures data infomation) on all datasets and model architectures. And as increases, the performance is better since the lower bound is tighter.
For the qualitative analysis in Fig 5, it’s worth noting that for IWAE, it has a larger spredout of the latent distribution and sometimes different output digits, e.g., “6” for “0”. This demonstrates the relaxation of the heavy panelization on the outliers, contrary to the example in Fig 2.

In a grid search of different combinations of with fixed as , we can see neither or makes the optimal solution in Fig 6. In other words, the ELBO objective should consider both the sampling inside and outside , which are beneficial to the generative network and inference network respectively.
Conclusion
IWAE uses a simple technique, moving the average operation inside , to achieve a tighter lower bound. The importance weights relaxes the heavy penalization on the posterior samples which fail to explain the observation. Although IWAE effectively reduces the bias, it’s shown that the sampling inside is only beneficial to the generative network, but hurts the inference network. Therefore, to combine the ELBO in VAE and IWAE, the IWAE variants, MIWAE, CIWAE and PIWAE are proposed. The final results demonstrate that the optimal objective needs the sampling inside and outside to be both greater than one. These works takes a deep look into the ELBO objective in VAE and reveal its role in the learning process.
References
- [1] 2014 (ICLR): D. Kingma, M. Welling, Auto-Encoding Variational Bayes, ICLR, 2014.
- [2] 2016 (ICLR): Y. Burda, R. Grosse, R. Salakhutdinov. Importance Weighted Autoencoders. ICLR, 2016.
- [3] 2018 (ICML): T. Rainforth, A. Kosiorek, T. Le, C. Maddison, M. Igl, F. Wood, Y. Teh, Tighter Variational Bounds are Not Necessarily Better. ICML, 2018.