VAE4 Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
Shengyu Feng (shengyu8@illinois.edu)
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
This is the best paper [2] in ICML 2019, which incurred huge controversy at that time. It heavily criticizes the previous works on disentanglement, but some claims of it are regarded to be too strong. I will introduce those assumptions challenged by this paper. Although I find some arguments not well supported, most of the conclusions from this paper are actually valuable and inspiring for the later works on the disentanglement.
Introduction to disentanglement
There’s actually no formal definition of disentanglement right now. Intuitively, disentangled representation should be compact and interpretable, where each dimension of the representation is informative and independent. Consider two independent random variables and , then is an entangled representation while is a disentangled representation. These two representations actually contain the same information about and but the disentangled representation is expected to be more interpretable and more useful for downstream tasks, such as controllable sample generation and robot manipulation.
For a long period, many VAE-based methods like -VAE [1], with additional tricks to encourage the dimension independence of the latent representation, have been proposed for disentanglement. But all these methods are based on some common assumptions and they are not carefully verified.
Disentanglement is impossible without inductive bias
This paper claims that, for an arbitrary generative model, the disentanglement is actually impossible. For each disentanglement representation , there exists an inifinite family of bijective functions , where is entangled but it shares the same marginal distribution with . In other words, there are infinitely many generative models which have the same marginal distribution for the observation , and without inductive bias, there’s no guarantee the one we obtain gives the disentangled representation. This theorem is also similar to the well-known “No free lunch theorem” [9]. Therefore, it’s necessary for each disentanglement method to clearly define its inductive bias.
Challenging the common assumptions behind disentanglement learning
This paper investigates several assumptions behind the disentanglement learning. It considers 6 distanglement methods, including -VAE [1], AnnealedVAE [6], FactorVAE [5], -TCVAE [3], DIP-VAE-I and DIP-AVE-II [4]. It also uses 6 metrics for measuring disentanglement, including BetaVAE metric [1], FactorVAE metric [5], Mutual Information GAP (MIG) [3], Modularity [7], DCI Disentanglement gap (named as “disentanglement metric” originally) [8], and SAP score [4]. The experiments are conducted on datasets dSprites, Cars3D, SmallNORB, Shapes3D, Color-dSprites, Noisy-dSprites and Scream-dSprites.
Mean representation of the latent variables are correlated
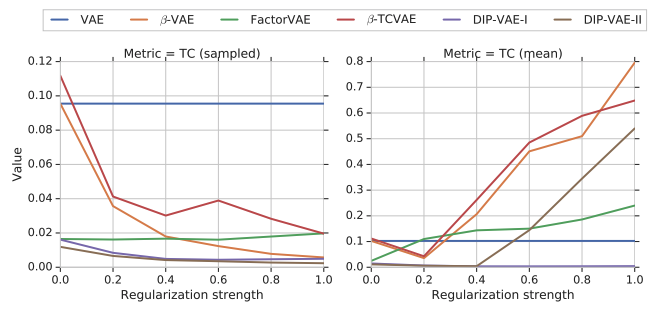
It’s a common practice to use the mean vector of the Gaussian encoder as the representation of the latent variable for evaluation. However, it turns out that although the samples from the Gaussian encoder have uncorrelated dimensions, the mean vector doesn’t internally have this property. Constrained by a stronger regularization, as shown in Fig 1, the total correlation, which measures the correlation among dimensions, of the sampled representation indeed goes down (left) but the total correlation of the mean representation increases (right) instead, except for DIP-VAE-I which directly optimizes the covariance matrix of the mean representation to be diagonal.
Disentanglement metrics are correlated
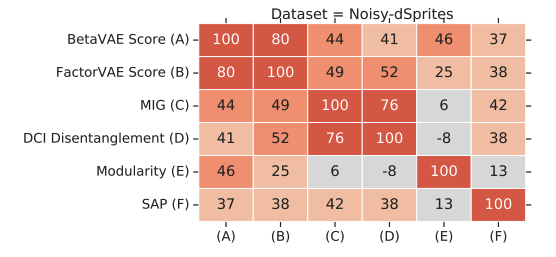
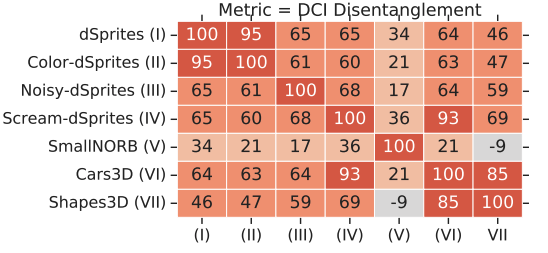
The second question is whether all these metrics measuring the disentanglement are correlated. And the results give the positive answer. All metrics except Modularity are mildly correlated.
Importance of models and hyperparameters
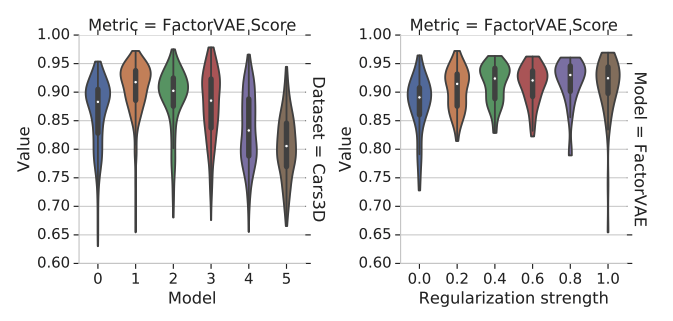
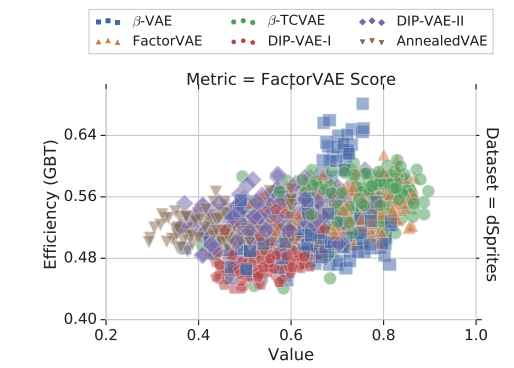
All these methods claim that they get a better disentangled representation, but whether the improvement in their metrics is from more disentanglement remains unknown. In the experiment, each model is run over different random seeds, but it turns out that these methods have large overlappings (left in Fig 3) in their performances. In other words, a good random seed is more meaningful than a good objective. The same conclusion holds for the hyperparameter (right in Fig 3).
Recipes for hyperparameter selection
The paper now considers the strategy to select a good hyperparameter for a model. However, all these metrics require a substantial amount of labels or a full generative model, so we need to consider the hyperparameter selection in an unsupervised manner. Unfortunately, no model could dominate others all the time and there does not exist a hyperparameter selection strategy that works consistently well as shown in Fig 4. Additionally, there’s also no strategy to identify a good and a bad run for different random seeds.
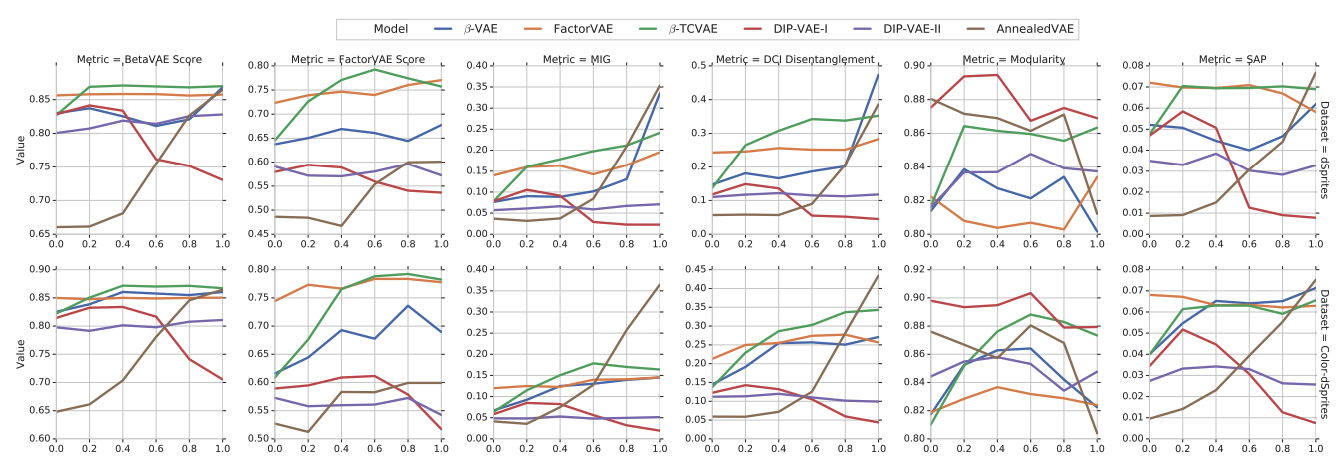
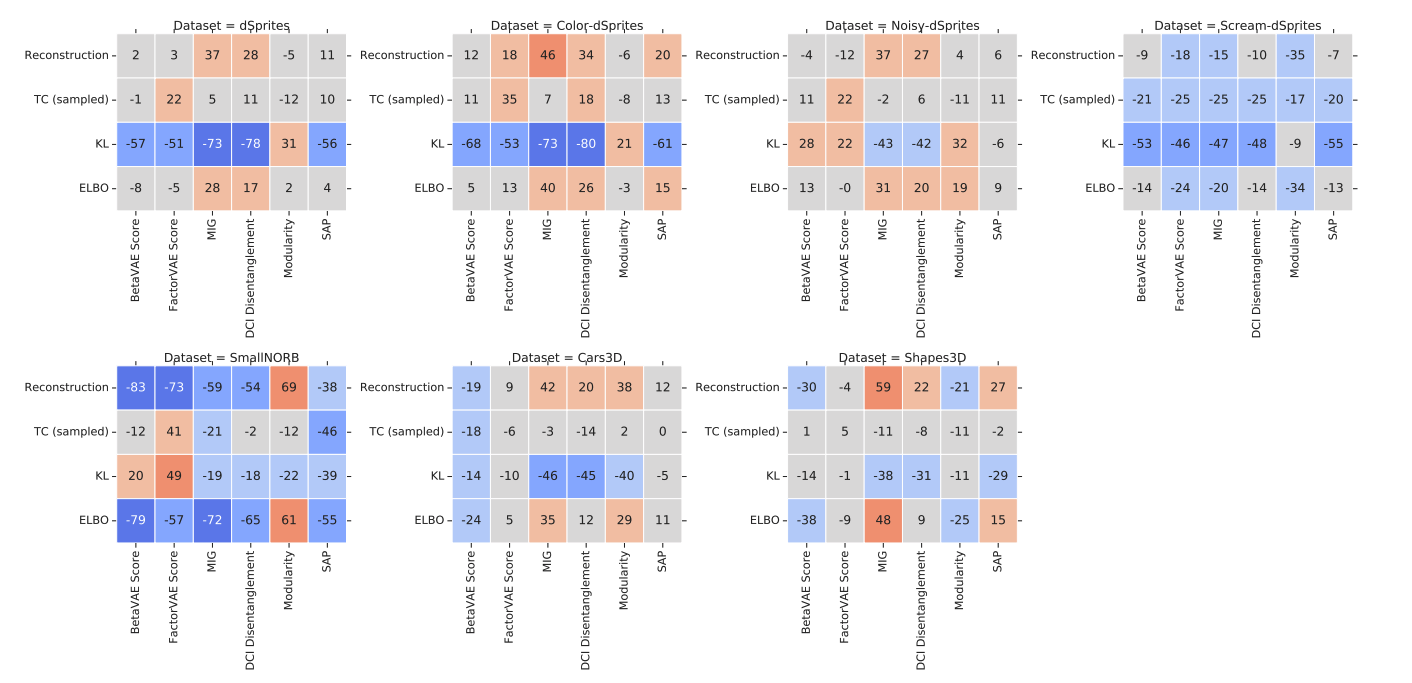
Specifically, the paper investigates the unsupervised losses and transfer performances, which can also serve as a strategy to select the hyperparamter without supervision on the target dataset. For the unsupervised losses, including the reconstruction error, KL divergence between the prior and the approximate posterior, evidence lower bound (ELBO), and the estimated total correlation of the sampled representation, none of them are actually correlated with the disentanglement metrics (Fig 5).
Benefits of disentanglement
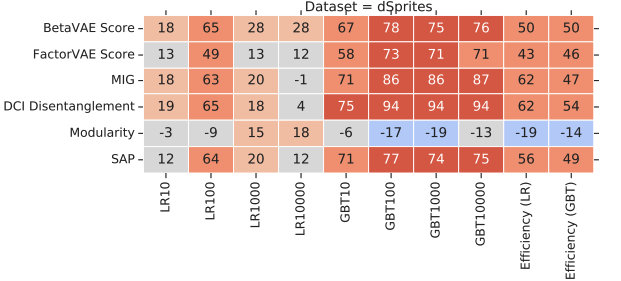
Finally, this paper explores the benefits of the disentanglement. The disentangled representation is intuitively believed to be more useful for downstream tasks, and able to reduce the sample complexity of learning. In the experiments, the downstream performances show high correlation with the disentanglement scores (Fig 7), but the authors are careful with the conclusion and doubts the source of the correlation, which could be either the disentanglement or the relevant information embedded in the representation. I think the experiments here are incomplete, where authors can actually build entangled representations from the disentangled ones and evaluate the performance of the entangled representations. This comparison could give the idea where the correlation comes from.
Future directions
This paper proposes three principles for the future work on the disentanglement based on the experiments before.
-
Inductive biases and implicit and explicit supervision. As proved by this paper, the inductive bias is necessary for the disentangled methods, which should be made clear in the later works. Besides, it’s demonstrated by the experimental results that it’s impossible for the hyperparameter selection under no supervision, the supervision parts should also be explicitly specified.
-
Concrete practical benefits of disentangled representations. Previous works take it for grant that disentangled representation is better, however, this paper points out its benefits is not clear yet and quite data dependent. Therefore, the concrete benefits of disentangled representations should be specified under each context.
-
Experimental setup and diversity of data sets. It’s shown that no model can consistently outperform others on all datasets, so it’s questionable whether these models really improve the disentanglement. A sound, robust, and reproducible experimental setup on a diverse set of data sets is needed to demonstrate the advantage of a disentangled method.
References
- [1] 2017 (ICLR): I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, A. Lerchner. beta-VAE: Learning basic visual concepts with a constrained variational framework. ICLR, 2017.
- [2] 2019 (ICML): F. Locatello, S. Bauer, M. Lucic, G. Rätsch, S. Gelly, B. Scholkopf, O. Bachem. Challenging common assumptions in the unsupervised learning of disentangled representations. ICML, 2019.
- [3] 2018 (NeurIPS): T. Chen, X. Li, R. Grosse, D. Duvenaud. Isolating sources of disentanglement in variational autoencoders. NeurIPS, 2018.
- [4] 2018 (ICLR): A. Kumar, P. Sattigeri, A. Balakrishnan. Variational inference of disentangled latent concepts from unlabeled observations. ICLR, 2018.
- [5] 2018 (ICML): H. Kim, A. Mnih. Disentangling by factorising. NIPS, 2017.
- [6] 2017 (NIPS): C. Burgess, I. Higgins, A. Pal, L. Matthey, N. Watters, G. Desjardins, A. Lerchner. Understanding disentangling in -VAE. NIPS, 2017.
- [7] 2018 (NIPS): K. Ridgeway, M. Mozer. Learning deep disentangled embeddings with the f-statistic loss. NIPS, 2018.
- [8] 2018 (ICLR): C. Eastwood, C. Williams. A framework for the quantitative evaluation of disentangled representations. ICLR, 2018.
- [9] 1997 (IEEE): D. Wolpert, W. Macready. No Free Lunch Theorems for Optimization. IEEE Transactions on Evolutionary Computation, 1997.